昨天對 ElasticSearch做了一些簡單的小介紹,今天聊聊 ElasticSearch的資料組成以及架構
資料組成:
備註 : 在後期官方取消了 Type 的應用,並統一以 (_doc) 管理,而原來的 Type就類似於一般資料庫中的 Table,官方給出的解釋是,如果一個 Node中,又依據資料拆成多個 Type不符合原本理念,效能也較差,故取消。
比較圖 :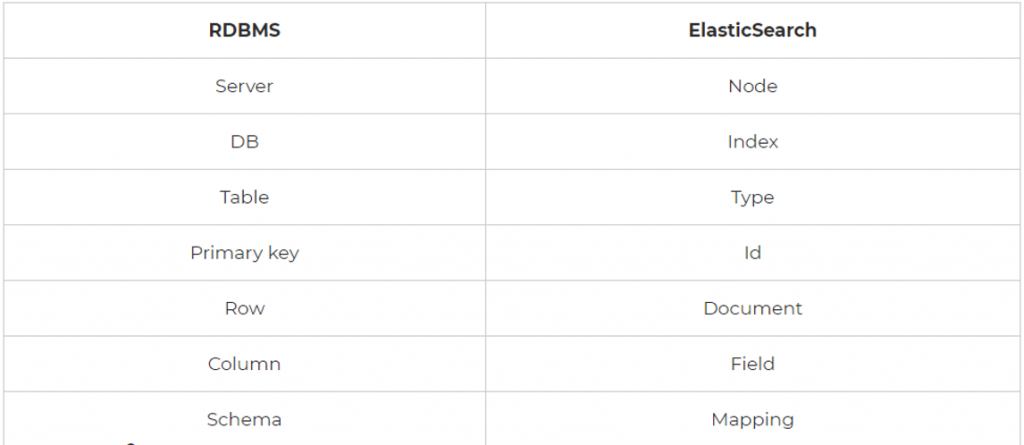
架構觀念
Shard : 分片,Elasticsearch 提供分散式搜尋的基礎,將一個完整的 Index 分成若干部分,儲存在相同或不同的 Node 上,這些組成 Index 的部分就叫做 Shard。
Replica : Shard 的備份,所以一個 Index 的 Shard 數量就等於 Shard × (1 + Replica)。
示意圖 :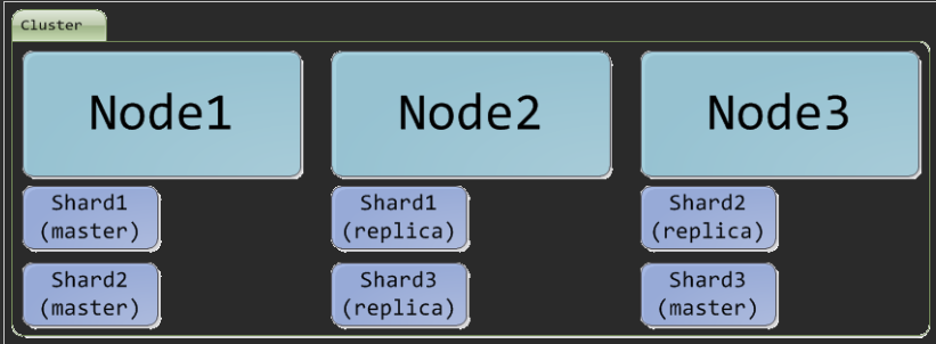
Recovery :
當有節點加入、退出叢集(Cluster)或故障節點重新啟動時,Elasticsearch 會根據各節點 (Node) 的負載情況,對索引分片 (Shards) 進行重新分配
示意圖 :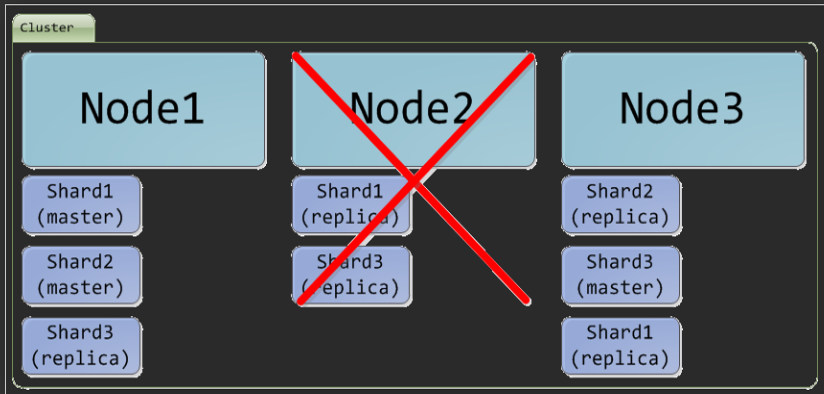
ELK Stack
Logstash:可收集各式各樣的 Log 或是資訊,並根據你的 Log 來 Parser 成你要的資料欄位
Kibana:視覺化與圖形化的方式來顯示各種 Log
Beats:針對特定要收集的 Log,官方量身定做的輕量級日誌收集與轉送套件
示意圖 :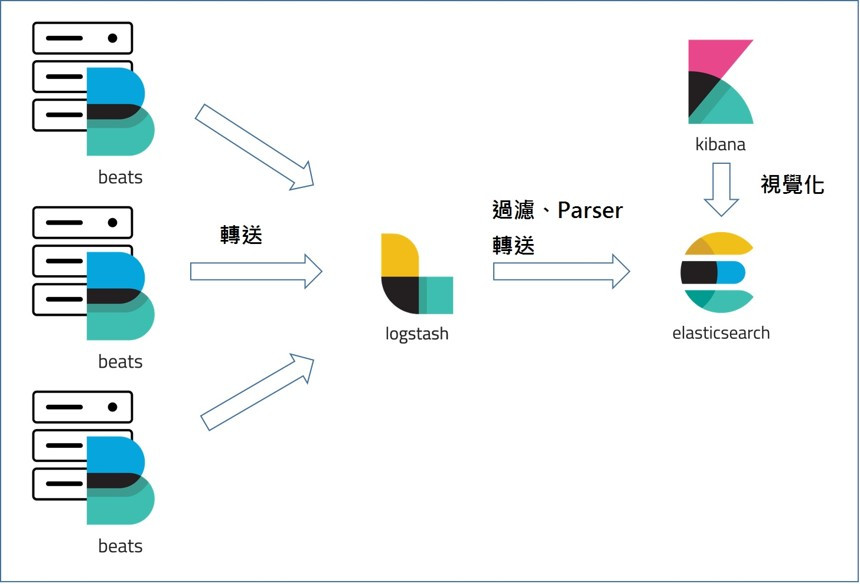
資料結構大致上,明天來進行實作~
來源 :
https://www.dotblogs.com.tw/supershowwei/2015/12/01/112117
https://zhuanlan.zhihu.com/p/72974595
https://godleon.github.io/blog/Elasticsearch/Elasticsearch-getting-started/
https://blog.toright.com/posts/5319/fulltext-search-elasticsearch-kibana-bigdata.html


 iThome鐵人賽
iThome鐵人賽